
Research Keywords
The word cloud image below was generated from the abstract of our papers published since 2023. This can provide a quick snapshot of our lab’s research interests.

Heterogeneous Memory Systems
The ongoing evolution of computing systems is fundamentally reshaping the role of memory. Traditional CPU-centric architectures built around homogeneous commodity DRAM have given way to heterogeneous platforms that integrate GPUs, domain-specific accelerators, and emerging memory technologies such as processing in/near memory. At the same time, memory hierarchies are expanding into multiple tiers, spanning on-package DRAM and disaggregated memory via CXL. These changes challenge the long-standing assumptions that underpin conventional memory management methods. In this new landscape, existing memory management and virtualization mechanisms designed for traditional host memory have become a critical bottleneck, introducing inefficiencies, constraining scalability, and obscuring the performance potential of future computing systems. While we envision that memory management must ultimately be redesigned to support modern computing environments, our research pursues a pragmatic path forward by identifying and resolving inefficiencies in current system-level memory management, paving the way toward more adaptive, efficient, and scalable memory architectures.

Processing in/near Memory
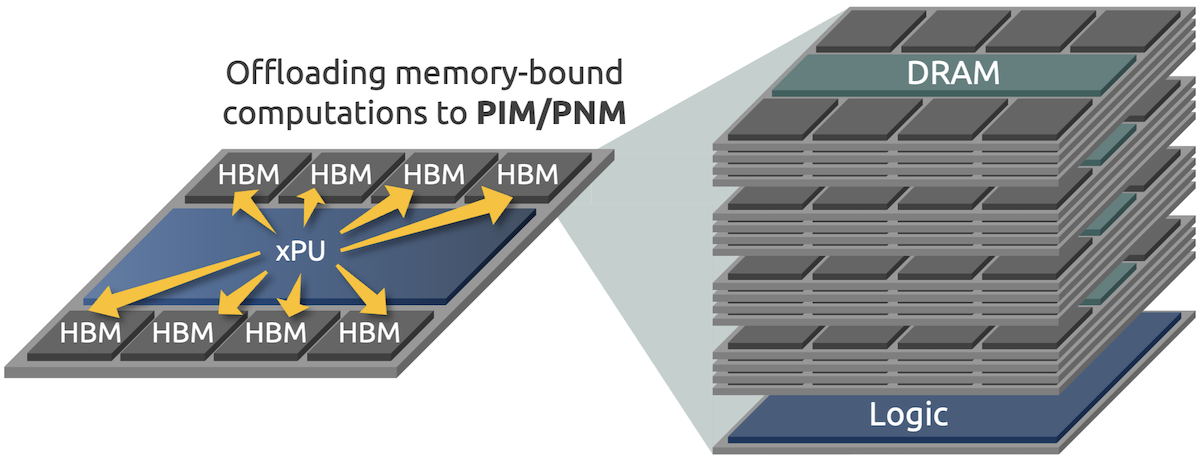
Data movement has become a fundamental bottleneck in computing systems. Conventional architectures increasingly expend a significant fraction of their energy and execution time on transferring data between memory and processing units, which continues to escalate as applications operate on ever-larger datasets. Processing-in-memory (PIM) and processing-near-memory (PNM) represent a decisive architectural shift that rethinks the placement of computation. By embedding compute capabilities directly within or adjacent to memory banks, PIM/PNM dramatically reduces data movement, lowers access latency and energy consumption, and unlocks the high internal bandwidth of memory devices. These advantages align naturally with today’s dominant memory-bound workloads, including attention mechanisms in large language models and other data-intensive analytics. Our research advances the vision of PIM/PNM as an essential element of heterogeneous computing. Rather than treating PIM/PNM as isolated accelerators, we focus on system-level foundations, such as memory virtualization support and optimized data placement, to make PIM/PNM technologies efficient, scalable, and practical for future computing systems.
Large Language Model Acceleration
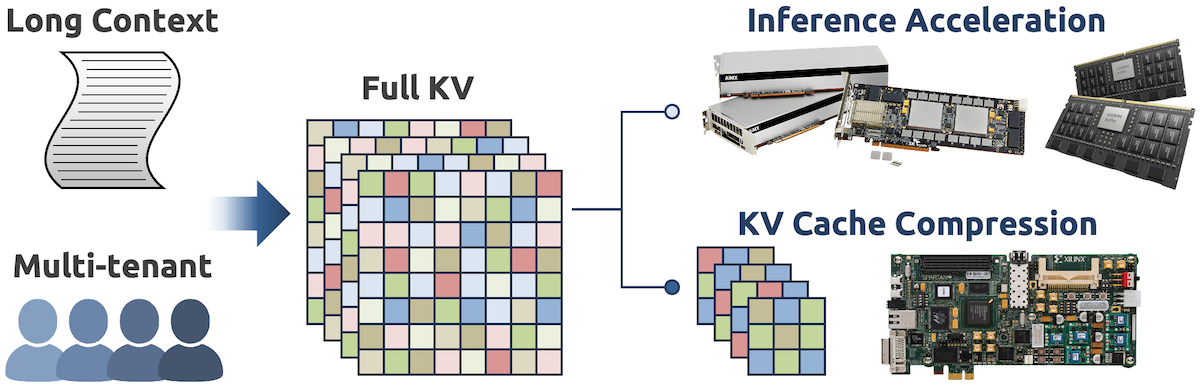
Large language models (LLMs) are rapidly redefining the performance requirements of computing systems, with inference tasks emerging as dominant and cost-critical workloads. A central bottleneck in LLM execution is the key-value (KV) cache used by attention mechanisms, which grows linearly with sequence length and model size, placing immense pressure on memory capacity and bandwidth. As LLMs scale toward long-context and multi-tenant settings, simply storing and accessing full KV caches becomes increasingly unsustainable, limiting throughput, latency, and scalability. Our research addresses this challenge by approaching LLM acceleration from a memory-centric perspective. We focus on devising novel KV cache compression/selection algorithms that carefully balance accuracy, latency, and memory bandwidth, while exposing opportunities for efficient hardware acceleration. Complementing algorithmic innovation, we pursue hardware prototyping to explore PNM designs that natively support KV cache compression. Through the co-design of algorithms and hardware, we aim to develop practical and scalable solutions for LLM acceleration that can significantly reduce memory overhead while preserving model quality and efficiency.
Machine Learning for Systems
While much of computer systems research has focused on designing efficient and scalable hardware to support machine learning (ML) workloads, rapid advances in ML techniques themselves create new opportunities to apply data-driven analytics to the modeling and optimization of computer systems. Our research interests lie in leveraging these advances to tackle long-standing challenges in computer systems, particularly in power efficiency and reliability, which are worsening with continued technology scaling. All the innovative changes in computer designs, transitioning from traditional CPU-oriented systems to massively parallel GPUs, data-centric accelerators, and processing-in/near-memory, have been largely driven by the need to improve energy efficiency. This demand has become increasingly urgent as power consumption emerges as a fundamental limiting factor across computing platforms, from mobile devices to warehouse-scale datacenters. In the meantime, continued increases in transistor density and system complexity, such as the adoption of chiplet-based integration, intensify reliability issues, from soft errors (e.g., transient bit flips) to permanent hard failures that threaten system lifetime reliability. We believe these long-standing, unresolved challenges can be effectively mitigated through ML-based modeling and optimization techniques, enabling more power-efficient and reliable computer systems.